
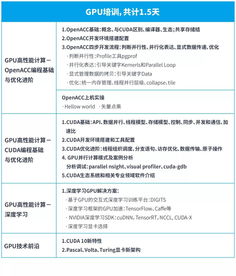
如何使用gpu进行并行计算gpu并行计算的优化
算法模型
2024-04-06 15:00
856
联系人:
联系方式:
GPU并行计算优化:提高性能与效率的关键策略
随着科技的不断发展,计算机图形处理单元(GPU)已经成为了并行计算领域的重要力量。GPU具有大量的并行处理核心,能够同时执行多个任务,从而实现高效的计算性能。然而,要充分发挥GPU的潜力,还需要对并行计算进行优化。本文将探讨GPU并行计算的优化策略,以提高性能和效率。
一、选择合适的编程模型
在GPU上进行并行计算时,选择合适的编程模型至关重要。目前主流的GPU编程模型有CUDA、OpenCL和DirectCompute等。其中,CUDA是NVIDIA公司推出的专有编程模型,适用于NVIDIA的GPU;而OpenCL则是一种跨平台的开放标准,可以在多种硬件上运行。在选择编程模型时,需要考虑目标硬件平台、开发团队的技术背景以及项目的具体需求。
二、数据传输优化
在进行GPU并行计算时,数据需要在CPU和GPU之间传输。由于GPU通常具有独立的内存空间,因此数据传输成为了影响性能的重要因素。为了减少数据传输的开销,可以采取以下措施:
- 减少数据传输量:通过压缩算法或只传输必要的数据来降低数据传输量。
- 避免频繁的数据传输:尽量在一次数据传输后完成多个计算任务,以减少数据传输的次数。
- 使用零拷贝技术:利用GPUDirect等技术实现CPU和GPU之间的直接数据传输,避免额外的内存拷贝操作。
三、线程调度优化
在GPU并行计算中,线程调度是影响性能的关键因素之一。合理的线程调度策略可以提高GPU的计算效率。以下是一些线程调度的优化建议:
- 合理分配线程块大小:根据GPU架构的特点和计算任务的特性,选择合适大小的线程块,以充分利用GPU的计算资源。
- 避免分支预测错误:尽量减少条件判断语句的使用,或者采用向量化等技术来消除分支预测错误的影响。
- 减少全局同步开销:尽量避免不必要的全局同步操作,可以通过局部同步或者流水线技术来实现更高效的线程协作。
四、内存访问优化
内存访问速度是影响GPU并行计算性能的重要因素之一。为了提高内存访问效率,可以采取以下措施:
- 合理利用缓存:充分利用GPU的各级缓存结构,将常用的数据存储在缓存中,以减少对主内存的访问次数。
- 优化内存布局:根据数据的访问模式和访问频率,合理安排数据的内存布局,以减少内存访问冲突和数据传输延迟。
- 使用共享内存:对于线程块内的数据共享,可以使用共享内存来减少对全局内存的访问次数,从而提高内存访问效率。
五、总结
GPU并行计算的优化是一个复杂且持续的过程,涉及到编程模型的选择、数据传输、线程调度和内存访问等多个方面。通过对这些方面的持续优化和改进,我们可以充分发挥GPU的强大计算能力,提高并行计算的性能和效率。在未来的发展中,随着硬件技术的不断进步和软件工具的不断完善,我们有理由相信GPU并行计算将在更多领域发挥重要作用,为科学研究和工程实践提供强大的支持。
GPU并行计算优化:提高性能与效率的关键策略
随着科技的不断发展,计算机图形处理单元(GPU)已经成为了并行计算领域的重要力量。GPU具有大量的并行处理核心,能够同时执行多个任务,从而实现高效的计算性能。然而,要充分发挥GPU的潜力,还需要对并行计算进行优化。本文将探讨GPU并行计算的优化策略,以提高性能和效率。
一、选择合适的编程模型
在GPU上进行并行计算时,选择合适的编程模型至关重要。目前主流的GPU编程模型有CUDA、OpenCL和DirectCompute等。其中,CUDA是NVIDIA公司推出的专有编程模型,适用于NVIDIA的GPU;而OpenCL则是一种跨平台的开放标准,可以在多种硬件上运行。在选择编程模型时,需要考虑目标硬件平台、开发团队的技术背景以及项目的具体需求。
二、数据传输优化
在进行GPU并行计算时,数据需要在CPU和GPU之间传输。由于GPU通常具有独立的内存空间,因此数据传输成为了影响性能的重要因素。为了减少数据传输的开销,可以采取以下措施:
- 减少数据传输量:通过压缩算法或只传输必要的数据来降低数据传输量。
- 避免频繁的数据传输:尽量在一次数据传输后完成多个计算任务,以减少数据传输的次数。
- 使用零拷贝技术:利用GPUDirect等技术实现CPU和GPU之间的直接数据传输,避免额外的内存拷贝操作。
三、线程调度优化
在GPU并行计算中,线程调度是影响性能的关键因素之一。合理的线程调度策略可以提高GPU的计算效率。以下是一些线程调度的优化建议:
- 合理分配线程块大小:根据GPU架构的特点和计算任务的特性,选择合适大小的线程块,以充分利用GPU的计算资源。
- 避免分支预测错误:尽量减少条件判断语句的使用,或者采用向量化等技术来消除分支预测错误的影响。
- 减少全局同步开销:尽量避免不必要的全局同步操作,可以通过局部同步或者流水线技术来实现更高效的线程协作。
四、内存访问优化
内存访问速度是影响GPU并行计算性能的重要因素之一。为了提高内存访问效率,可以采取以下措施:
- 合理利用缓存:充分利用GPU的各级缓存结构,将常用的数据存储在缓存中,以减少对主内存的访问次数。
- 优化内存布局:根据数据的访问模式和访问频率,合理安排数据的内存布局,以减少内存访问冲突和数据传输延迟。
- 使用共享内存:对于线程块内的数据共享,可以使用共享内存来减少对全局内存的访问次数,从而提高内存访问效率。
五、总结
GPU并行计算的优化是一个复杂且持续的过程,涉及到编程模型的选择、数据传输、线程调度和内存访问等多个方面。通过对这些方面的持续优化和改进,我们可以充分发挥GPU的强大计算能力,提高并行计算的性能和效率。在未来的发展中,随着硬件技术的不断进步和软件工具的不断完善,我们有理由相信GPU并行计算将在更多领域发挥重要作用,为科学研究和工程实践提供强大的支持。

